| |
ENC1
ectodermal-neural cortex 1| Gene | | Official Symbol | ENC1 | | Official Full Name | ectodermal-neural cortex 1 | | CGNC ID | 11082 | | also known as | ectoderm-neural cortex protein 1|ectodermal-neural cortex (with BTB-like domain)|ectodermal-neural cortex 1 (with BTB domain)|ectodermal-neural cortex 1 (with BTB-like domain) | | gene type | protein-coding |
| | Genomic Map | | | Sequence Information | | | Gene Expression | | | Orthology | | | Gene Ontology | | Molecular Function | | | Biological Process | | | Cellular Component | |
| | Links to other databases | |
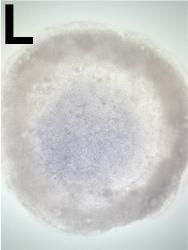
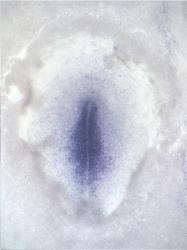
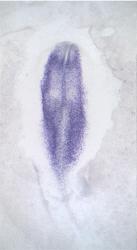
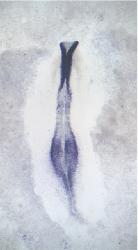
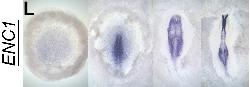
| GEISHA Id | ENC1.Trevers.2023 | Data Source | GEISHA ISH Analysis | | Complete cDNA Template Probe | show GGGGCAGAGCTGCGGCTCGGCGGTGCCAGCAGCAGCCGCCCGTTCTCCCGTCCTCCTCTCCTCCTTCCCCGCCGCGGTC
CGCCTCCTGCTGCCGGCACCACCTACGCCGGCCGCCTCTCCGCACGGCCGTCTCTCCCTTCCCATGCGCGGAGGCCGAG
GGACGCCCGCTCGGCAGCAGCCGCTGTGTGGAAGAAAATGTCAGTCAGCATGCATGAAAATCGCAAATCTAGGGCCAGT
ACTGGCTCCATAAACATATACTTATTCCACAAGTCATCCTATGCTGATAGCGTCCTGACTCACCTGAACCTTCTGCGTC
AGCAGCGCCTCTTTACAGATGTTCTCCTCCATGCTGGGAACAGGTCGTTCCCCTGCCACAGGGCTGTCCTGGCTGCCTG
CAGCCGCTATTTTGAAGCGATGTTCAGTGGAGGACTGAAAGAGAGCCAGGATAGCGAAGTCAACTTCCATAACTCCATT
CACCCAGAGGTCTTGGAGCTGCTCCTGGACTATGCATATTCCTCCAGGGTTATCATCAATGAGGAAAACGCAGAGTCGC
TGCTGGAGGCTGGTGACATGCTGGAGTTCCAGGACATTAGGGATGCTTGTGCAGAGTTTCTGGAGAAGAACCTTCATCC
TACCAACTGTCTTGGCATGCTCCTGCTGTCAGATGCTCACCAGTGCACCAAGCTTTACGAGCTCTCTTGGAGGATGTGC
CTTAGCAACTTCCAGAGTATCAGTAAAAGTGAAGACTTCCTCCAGCTGCCCAAAGACATGGTAGTGCAGCTCCTTTCCA
GTGAAGAATTAGAAACCGAAGATGAAAGGCTCGTGTATGAATCGGCTATCAACTGGGTCAACTATGACCTGAGTAAGCG
TCACTGTTACCTGCCCGAGCTACTGCAGACGGTGAGACTGGCCCTCTTGCCAGCCATATATCTGATGGAGAACGTGGCG
ATGGAAGAACTTATCACCAAGCAAAGGAAAAGCAAAGAGATAGTAGAAGAATCGATACGATGCAAGTTAAAGATCCTAC
AGAATGATGGAGTGGTCACTAGTTTGTGTGCCAGACCCCGCAAAACTGGCCATTCTCTTTTCCTTCTGGGTGGCCAGAC
TTTCATGTGTGACAAGCTGTACCTGGTGGACCAGAAGGCAAAGGAGATCATTCCGAAGGCTGACATACCGAGTCCGCGG
AAAGAGTTCAGTGCTTGTGCCATAGGCTGCAAAGTGTATATCACTGGGGGACGAGGGTCAGAAAATGGAGTCTCCAAAG
ATGTGTGGGTGTATGACACCCTTCACGAGGAGTGGTCAAAGGCTGCTCCCATGCTGGTGGCTCGCTTTGGCCATGGCTC
TGCTGAACTGAAGCACTGTCTGTACGTGGTAGGAGGACACACCGCAGCCACTGGATGCCTTCCAGCTTCCCCTTCAGTA
TCCTTAAAGCAAGTAGAACAGTACGACCCTGTGACCAACAAATGGACCATGGTTGCTCCGCTGCGAGAGGGAGTAAGCA
ATGCAGCTGTGGTCAGCGCAAAGCTGAAGCTGTTTGCTTTTGGAGGGACCAGCGTCAGCCACGACAAGCTGCCCAAAGT
TCAGTGCTACGATCAGTGTGAGAACAGATGGACGGTGCCAGCCACCTGCCCCCAGCCCTGGCGCTACACTGCTGCAGCT
GTCCTGGGTAACCAGATTTTTATTATGGGTGGAGATACGGAATTCTCTGCGTGCTCTGCTTACAAATTCAACAGTGAGA
CATACCAGTGGACTAAGGTGGGAGACGTGACAGCCAAGCGGATGAGCTGCCACGCAGTGGCATCTGGAAACAAGCTGTA
TGTTGTTGGAGGCTACTTTGGCATTCAGAGATGCAAAACACTGGACTGCTATGATCCCACTCTGGACGTATGGAACAGC
ATAACAACCGTGCCCTACTCGCTGATTCCCACGGCATTCGTCAGCACATGGAAGCACCTCCCCTCATAATTGTGTGTGT
GTGTTGCAATTAGAAATCATCAGTTTACTCCACTGTTGGGAGAAGAGAATTGGAACCTCGGATCTGGATAAATGGTTTT
AATGAAGAAAAAATCGCTCAGCATCTCTTGCATTTGAAGAAAATCATCCGCACCTTGTAAATTATCTAAACTACACATG
AAGGAACGGGAGGAAAAAACTGTCTTCTGGACTTCAGCACATGGTTTAAATACGAATGAGTGAACCTATGATCTGGTCC
TTGTGCTATTAATTGTGGATTAATGCCAATATTAATCAGTCCTTCAGAAGAGAGAAAGAAGAGACGAGACTTCTCTGAG
CAGTGCAGCACACGGCTCTTGATCTTTGCGGACTGCTGTTTGTATGAGAAATTTGAAATGGTTGTCACTCCCCTTTGTG
ATGACTTGAAGCGTCAGCGCCAGCTGCAGGGTAGCAGGCTGGGTCAGAATCAGCGGGATGAAGGGAGCTGTGCTGCTGG
AGAACTCTGCAAGCCAGAGGTGCTTGTCTGTGGGCATGCCTACGGCATCTCCTGGACCCTGCAGCGAATGACCTCCTGC
TGGAGGAGGAAGAGCACAGTGGCAAAATCTTCTTGCAACAGTGGGGAGCAAAAGTGTCACCCCCAAATGCTTCTTGTTC
CCTTTCCTCCCTGTATTTATAAGTAACCTGGACTGTCCTATTCTTGTTACGTTACTTGTTGTAGATACAGTTATTTATT
GTTCTGTGCTTGCATGCTGAAACAATGCCTGCAATTGTCTTCATGTTGTAAGGGCTTGTGTGAATTGTTGTATGTTTTG
CACATTTTGTGATTGCTGACTTGCTCTGCTGCACAAAGAAAGAAAACTGTTGGGTAACGGTGAGAGGGAGGGGTGGCTT
CCCGGTCAGAAATGGAAGGATTACAAAGCAGGATCTTAAGTTACACACTTAATAAAGGAAGAAGCCATGGAAGTCACTT
TCTCAGGCCACCAACTCCCCAGGTTGCATGTGGTGCATCTTGTAGATGGTGTCCTTGCTACATTTCATTCGCTGGTCAT
GCCTTTCAATTTCTTATCCGGAAATAGCCAAAACCATGTGCAGCTTTCTCTTTGTGCAGCTCCCTGATTGCAATGCAAA
TACTGTGGAATAGCTTCTGGATACCAAGCCCAGATGAAGTCATTGTCCAAAGTTATTTATTTATTTATTGGATTGGAGA
AGGGGATACCTACAGTTCAGCCACATTGACCCCAGTGAGTGGAGTGCGGCTGATTCAGGAATAAAAGTAAAAACCTCAA
GATATGTTAGAGATGAAGTCTTAAATGCAAGAGCAGCAATTTTGCACTGACTGGATTGCCTCATCCATCTGGATTTCAG
ATGATCAACTGAGTGGGCAAGAATCAAAGACCCAAGTGCTCTAGCAAATTCTCATGGGGATAGAAAATGAATTTCAAAG
CTCCTAGTCTTAAAAATAACCCTCAGACTGTTCTGCCTTTTCTCTTTCATTGCCAGGTATGTATATAAACACTCGGTTG
TTCAGAGTGTCTGATACAGCCCTCAGAAACCAACCTTTTAATTTTTTAAAGAAATTTGTTTCTTATCCGTCTGGTCTTG
AGACAGATACGAAGCTACTCTTTTCCTTCTGGATTTCAGAAGCTTATTTTTCACAGGTGCTTTCTTTGCCAGATTCTGT
TACAAAGCATGTATTGTATTGTGTTTTTCCCTAAATGTTTTTCTGGAGCCCAACTTGACTGGCACATTCAGTAACATGG
TTGGTGTGTGCTGCAGTATAAGTAAACAGCTGCATGCGTGCATGCAAAACAAAAATAGTCACATTGGTGATGTTTGCCT
TTCTGTGTGACAGTGGTGTAGCTGTAGTTGTGAAAGCTGTGTCATCTGAAAGTATTTACACTGGTCACTGGAAGTTTCT
CTGTGCTGCCTTATGTTTGACTTGCTGTTTGGAGTAGACCTTTACATTTCAGAAATAGAGTACTTGGCGTTCTGTGAAT
ACTCAGACAACGTTGATTAGCAAAGGCATTAGCAGCTTATTTTAAGGGTGAGGCCCAGCTAGATGCAAACAGTTACAGT
TCTTCTAGTTTAACTGATCTGTTGAAATGATAGATTAACAAAATGATAGATTAACAAAAAAAGAAAACCCAATAGCATC
CCCCCACCCCACATCAGCTCCTTTCTACTAGATGGCTTTGAGCAATAGAAAAACATCTTAGGTAGGATAGGTCTCCTCT
CTGCATCCCTTTGCATGCACAGGATGCCCTGCTGCTGGCTTGAGCCACTGGCGTCGTGCATCTCAGGGCTTGTGGGCAC
CAAATGAGCTGTCACGTCAGACACGTGTGTTTTGCATGTCCTCTCCCAGGTGCTACTGATGGTGCAAGGCATGGGGAAA
TGAGGAGCCAGGGCCCCTTCCTTGAATCAGGGCATCCAGATTAGAGGCCTGTTTTCCCTGTCAAACGGATGTAAGTCCA
GGTGCGAAGCCTCTCTGCACCTTGCTGCTCAGCTTACGGCACAAATCTGCTCTGTGGCACTATGTGGTTTCCAGAAGTG
GGATAAGCCTTCTGCAGCTGTTTCAAAGGTCTGCTTTCCTGCCCTTTGTATTAATTCCTGTGGGTAGGCTGGAGGAAGA
TGGAGTTGGGGTGGGCTTTTGGCTGTGGAGGGAAGGCACCGGGCTCTTGCTTGGAGCTGGTGTGGGAATCCCAGTGGCA
TGCTTGGCCATTCCAGTCCTGTGCACAGCCTGTGCTTTGAAGTGAAGGCGGTTCACAGCAGAGTGCACACAAAACCCTT
GGCATAAGACGAGAAGGTTCCTCTTATTCTGCGGGCTGGTTGCTGTAGAAACATGTAACAAAGGACAGCCTTCCTCTCC
TGGTATAAATGTGCAGCCCCTTTTCTCTAGGTTTGACACCTGTCTGAATAAGAGTGATTCGAGCAGAATAATGTTCTCT
TTCCTGGCTGTTGAAGAGATGTGGTTCATGTACTAAAAGGAAACTGTACAAGTGAAGAAGTAATATGTCTATGGTGTGT
CTTTTTGTTTGCTACTACATTTTAAGGTTTTGTAAAACTTGTATTTTTTTTTTTTCACAATGTGAAACTGAAGGTCAAT
AAATTATTAGAGATTTTCTCTCCATGGATCA | | Comments | Insufficient information provided in publication to verify exact sequence used to synthesize probe. Sequence below was obtained from NCBI (XM_015277651). |
MouseFrogFruit FlyZebra FinchZebrafish |
|