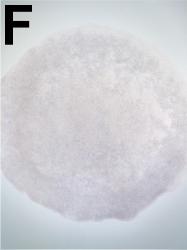
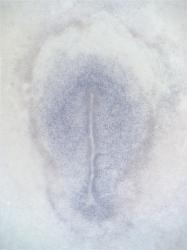
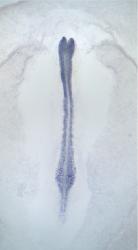
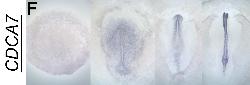
| |
CDCA7
cell division cycle associated 7| Gene | | Official Symbol | CDCA7 | | Official Full Name | cell division cycle associated 7 | | CGNC ID | | | also known as | cell division cycle-associated protein 7|LOW QUALITY PROTEIN: cell division cycle-associated protein 7 | | gene type | protein-coding |
| | Genomic Map | | | Sequence Information | | | Gene Expression | | | Orthology | | | Gene Ontology | | Molecular Function | | | Biological Process | | | Cellular Component | |
| | Links to other databases | |
| GEISHA Id | CDCA7.Trevers.2023 | Data Source | GEISHA ISH Analysis | | Complete cDNA Template Probe | show GCCCCTTCTGCCCCTGCCGCTTTGGCGCGAACCTTCATTTCCCGCCGCTCGTCTCGCCGTCAGCATGGCTCCGCAGCGC
CCGCAGCGCCGTTGCTCTGGAAGGAGAACCTTTACCACTTTCCGAAGTACCAAGCTGATTCCCATGGAGACATCCTCAT
CCTCTGATGACAGCTGCGACAGTTTTGGTTCTGACAGCTTTGCTAACACGAAGCGCAAGTTGAGGTCAGATGTTAGAGA
AGAGCTGGCCAAAATCTTTCACGAATCCTCTGACGATGAATCCTTCTGTGGCTTTTCAGAGAAGAAGATTGAAGGTGCC
TTGAAACTGGAGTCTGATTCAGAGGAGAACAACGTCAGCACTGGCAGAGAGGCATCTCTGAGACTGAGGAAATGCACTG
TTCCTCTCAAAGTAGCCATGAAGTTTCCACCTCGAAGATCAGGAAGGAGGAAGGCTGAGGTGGAATCTCTTCCTGAAGA
TGTGATGCCTGCTCCAGATTCAGACTCTGATTCTGAAGAGAAGGGCTCCCTGTTTTTAGAAAAGAGAGCGTTAAACATC
AAGGAAAACAAAGCAATGCTTGCAAAACTAATGGCTGAGTTGCAAAATGTTTCTGGTATCTTTGATGGGAGAAGATCAC
TGCCAGCTGCCAATAACGCACCAAAGCGACTTCCAAGGCGCTCGCTTCCCAGAAGTGCCTTGAGGAGGAACCCAGACAG
AAGTTCTCGGCCTCACACGAGATCCAGGTCCCTGATTGAAGGCCCTCCTACTCCTTTACCAGAGGAGGAAGATGATGAC
CGGTACCTCCTAGTGAGGAGGAGGAAGATGTCTGGTGAAGACCTGGAGCACGATGCCCAAACTCCCAGGAGAGGTCACC
GTGGTGCCATGGCTCTTCCACACATTGTGCGACCGGTTGAGGAGATAACGGAGGAAGAGCTGAGTAACATCTGTGGATC
TGCGAGAGAGAAAGTGTATAACAGAACCATGGGATCTACCTGTCATCAGTGTCGCCAAAAAACCATAGACACCAAGACC
AATTGTCGTAACCCTGATTGCATTGGGGTACGGGGCCAGTTCTGTGGGCCATGCCTCCGTAATAGGTATGGAGAAGATG
TCAGAACAGCATTGCTGGATCCAACCTGGAGGTGCCCACCATGCCGTGGAATATGCAACTGTAGCTTCTGCAGACAGAG
AGATGGCAGATGTGCTACGGGTGTCCTCGTCTATCTGGCCAAGTACCACGGCTATGATAATGTCCACGCCTACTTGAAA
GGTCTGAAACAAGAACTTGGAGTGGAAGACTGAAGTTGTGACTGCCTTTGACTTGCATACACCTTAACCAATGCCATAT
TATTGCCTACAGTGAATTGTTTAATCAAATGAGACTACAAAGCCAGTGCCTTGGCTCCCTCCACTTCTGAGTTTTAAAA
AAAAAAGGAAAGCATATTGCTGTGCAAATCATACTTTGAGAAACTGTTTCATAGAGCTTTGCCTGCAGGCCATTGTTTT
TTTTTTTTTAAATAACTTTTGTAAAACAAAAAATGAGTTATCATCAGTCCCTGCTTTTATGCCAATAACTTTTTCTTAT
CCTGAAAGAAGATGGGGCTTTAAGCCATTGGAGTTCTGTTCATGCATTGATCTGTACTGCAGGTTTATTTGTGCTTTGA
AGTTGATGACAAAAAGATAAGGATGTTCTGAACATTCAGGGCATTGTTCCCCACAGAACCAATTGGGGAAAGGTGTGTG
CTTAACTCCTCGCCAACTTCTGCTGCAATAGACTCTTACTGAACATAAATGATCAAACAGAAGCTAACAATCCTCCACA
ACAGCAATTCATTCGTAAGTTCAAAAAGGAAGGCCTAAAGGTTGCAGCTGAGCCGTCTCCAAGCATTAACATTTGGGTT
TATAGAGCACTTGAAGTGCACATTGGCCATTTTGAAGGAGTTTCTCTACTGAGTGATTTAAATTGCAGCAGAAGCAATT
AAGGGATAGACTCTTGTTTTCTGTGCTCTCTGAGATGAGAGGAGGCTGCTGCTGGAAGCTCCTACAGCACCAGCACTGC
TGTTGTGTAGTGGTGACTGATCTGAGTATGCGGGAATGCCTCATGGAGTGACCTCTGTTAAATTTCTATTGTTTTTTGG
GTTCTCTTTTTGGTTGTCCTTTCCCTTCTCTTGCTGCCAACTGTAGTAATGCTTCTGTACCAAATCAGCCTGGGGCTTA
GCCAAGTAGAGGAGTAGCTGATGTAGCCATTGGCCGATGGCAAGTGGGTGAACGGTGGTGACTTGTTAAATGCTATCAG
GAGAAGGGTCAGTGACAGTCACTCAATTTTCTTTTCTCAATGAGCAAAAATAGAAAGCAAAGGTTTTCTAAGCTACAAT
CCAGCTTAAAATGAATTATTCCTTGGCTTGCGTAGTGAAGCACAAATATGGTAATGTTCTCAAGAGACATGCCCCAGCT
GTGGTAACAGATGAGGAGGAACAATTGGTTGAAAAGGCTTTTAAAAATGAATAAAAAAGGAGATGTGTGCAGGTTGTGA
GCACTTAGAAACGTGGCTGGTGCTGTGGGCTCCTCTTTAACAACCCATCCGTACTTGTGTTTATTTCTGGCTATGTATG
ACTGTAGAAGGGCATTTTGTGTGATGCTGTTAATGGAGCCTGAAACAATACCTGGTGTTGTATGGACAGCATCTTCTAA
ATCTTGTGGAAAAGAAGGTGCCATGAAAACTGTCTGGAGATCCACAGTGAATACATGGGCTTAGTTTGGTAATGGAAGA
ATGCAATGTTACACATAATGTACAGTTGAATAGTAGGAAGAGTCAGCTTGGATTTATTGAGCACTAGAACAAAATGCAG
CTTCTGACCCTTCTGCTTGCACAGTATTTGCGCTCTGTATATGATGATCTGTGTTTTACACCTTTCTGGGAATTAGAGC
AGTGTGGGAAACAGAATATATTTGTCTCAGACTTGCAGATCTCGTTTATAAATCACCTGTGCTGTTGAGAATCTCCTGA
CCCCTGCTTCCATAGTGTGACTAGACGTGCAATCTTGGGTGGCGTGTGCCCTATTCTCCAGGTTCATCTCTTGAAGAAG
GAACTCTAGAAGTACACGTTCTGACAGATGAGAGTGATTTTTCTAATTGCTGTGCTTGCCTTCTGATTGCTGGAGTGTG
GAAGAACTGTGCTGAAAGCAAATCCCCGCTCCGTATCCTGGAGACTGCTGTATTTAGATTTCTTCCCATCGACAAATTT
CTGTATGAAGGTTTTTATTTTAAAAATAAAACTTTTTCTGGGTAAAA | | Comments | Insufficient information provided in publication to verify exact sequence used to synthesize probe. Sequence below was obtained from NCBI (XM_040704336). |
| | Data from NCBI Unigene EST Profile
Unigene ID: Gga.12693 |
MouseFrogFruit FlyZebra FinchZebrafish |
|