Quick Search
X XI XII XIII XIV 1 2 3 4 5 6 7 8 9 10 11 12
13 14 15 16 17 18 19 20 21 22 23 24
25 26 27 28 29 30 31 32 33 34 35 36
37 38 38 40 41 42 43 44
Gene Family QuickSearch
Human Disease Gene Search
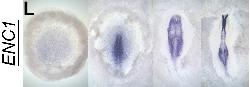
ENC1 Gene Summary Expression Transcript Levels Other Species Expression JBrowse Gene Official Symbol ENC1 Official Full Name ectodermal-neural cortex 1 CGNC ID 11082 also known as ectoderm-neural cortex protein 1|ectodermal-neural cortex (with BTB-like domain)|ectodermal-neural cortex 1 (with BTB domain)|ectodermal-neural cortex 1 (with BTB-like domain) gene type protein-coding
Genomic Map Sequence Information Gene Expression Orthology Gene Ontology Molecular Function Biological Process Cellular Component
Links to other databases
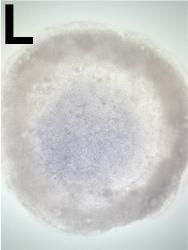
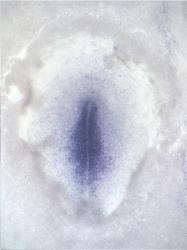
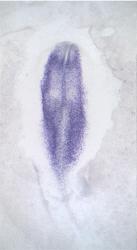
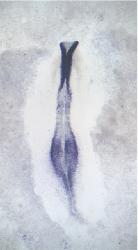
GEISHA Id ENC1.Trevers.2023 Data Source GEISHA ISH Analysis Complete cDNA Template Probe show GGGGCAGAGCTGCGGCTCGGCGGTGCCAGCAGCAGCCGCCCGTTCTCCCGTCCTCCTCTCCTCCTTCCCCGCCGCGGTC
Comments Insufficient information provided in publication to verify exact sequence used to synthesize probe. Sequence below was obtained from NCBI (XM_015277651).
Data from NCBI Unigene EST ProfileGga.49125
Mouse Frog Fruit Fly Zebra Finch Zebrafish